Summer Placement Diaries
During June and July, I carried out a two-month placement at one of the world’s most cutting edge companies in Machine Translation – Unbabel.

Unbabel works hand-in-hand with some of the world’s largest BPOs and outsourcing companies, easyJet, Booking.com, Rovio Entertainment, Under Armour, Pinterest to name a few. They get to translate up to 2 billion words per year for their customers. To achieve this goal there has to be a smooth network of engineers, linguists, translators, etc., working conjointly to ensure clients receive the message in their native language flawlessly. Unbabel is the rare example of a company combining the efficiency of MT and the experience and wisdom of human translators.
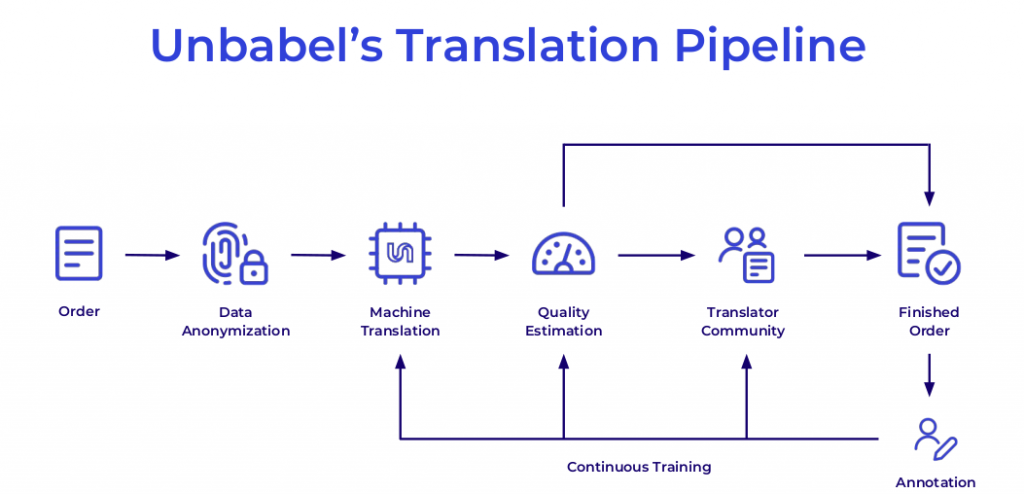
During the onboarding week, I had an insight into the company’s tools and processes. It was an opportunity to see in action all of the concepts I’ve learnt in the Machine Translation module (how is the MT model trained, MT evaluation, Quality Estimation, etc.). Additionally, I was shown the company’s latest developments, such as COMET – a framework for evaluating MT models, as well as the tools Unbabel uses, for example, to detect, annotate and anonymize named entities (NE), create and maintain translation memories, the platform where the translations in progress are tracked, the different pipelines (chat, tickets, FAQs), and all process occurring on them, sentence segmentation, tokenization, annotation, post-editing (PE), etc.